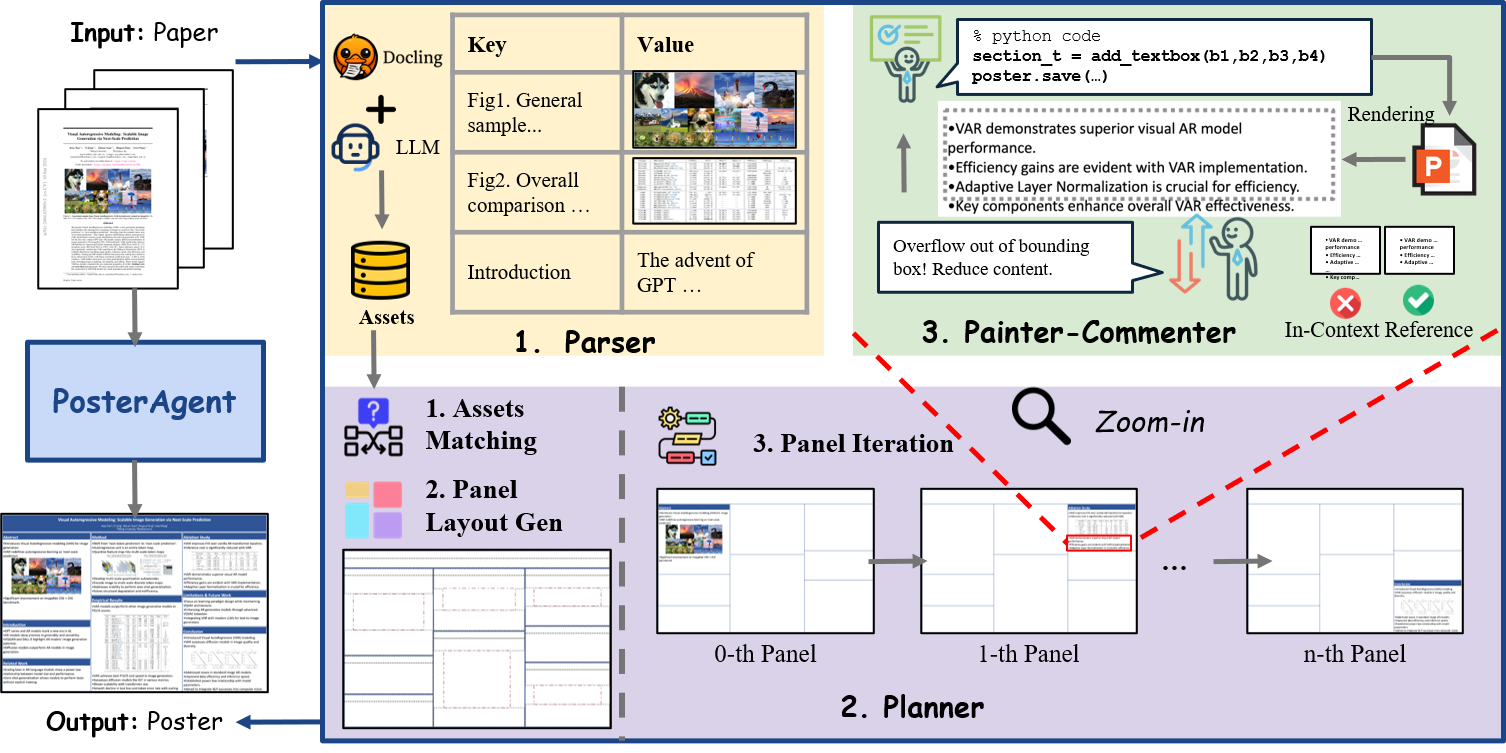
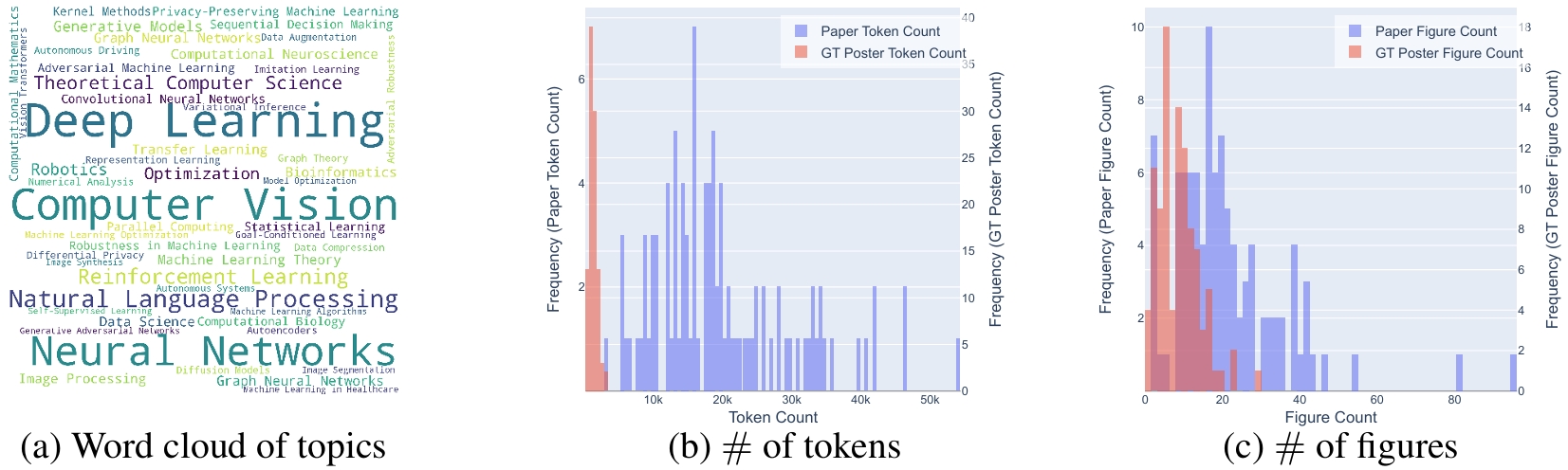
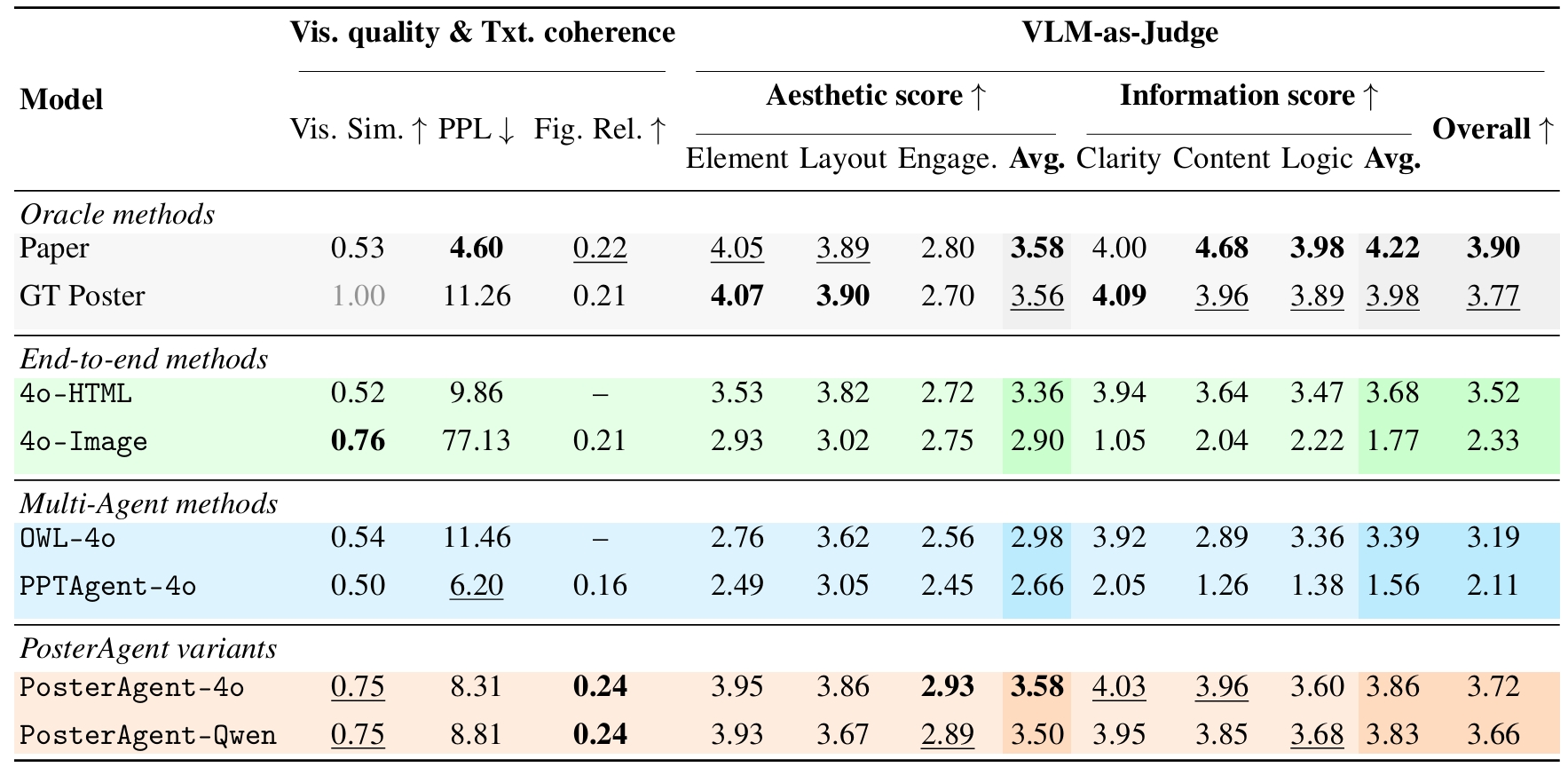
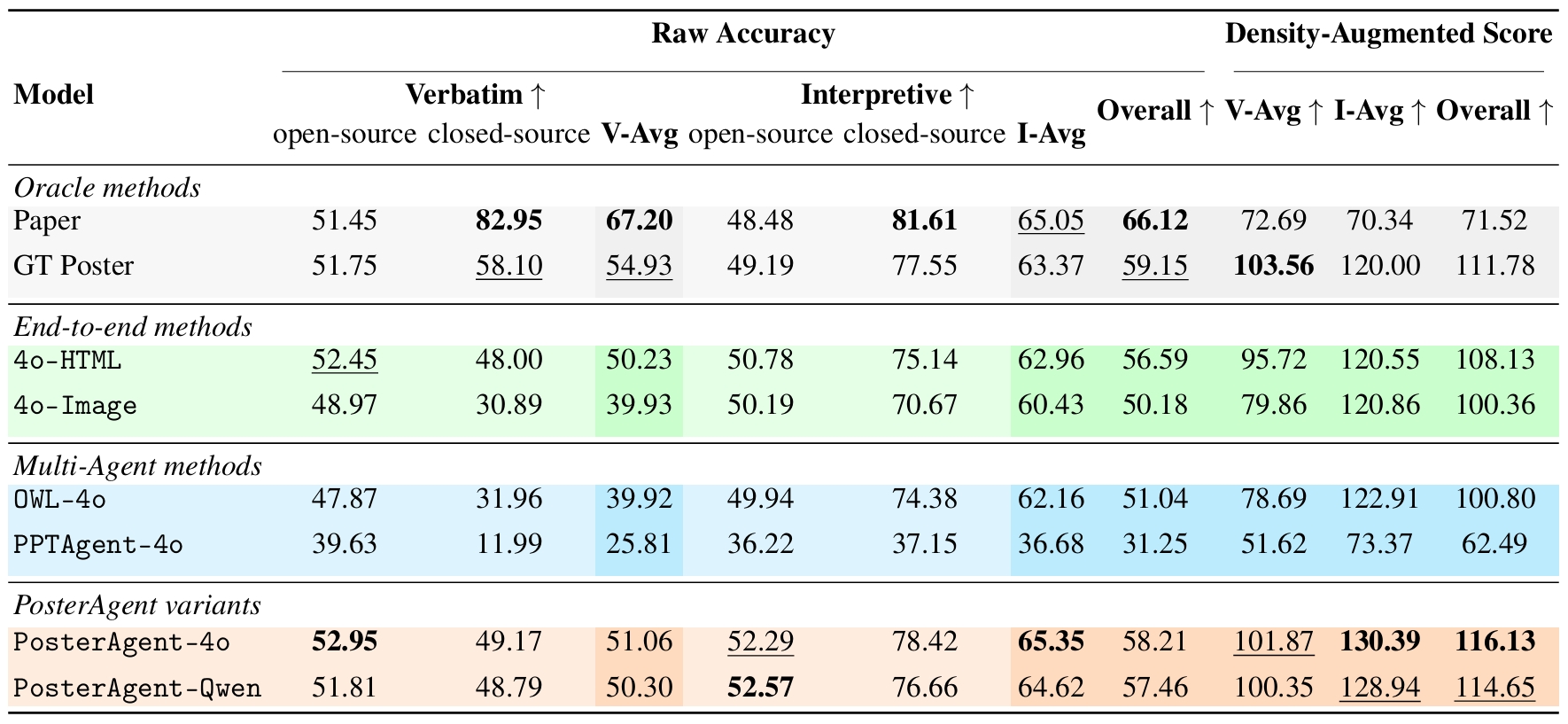
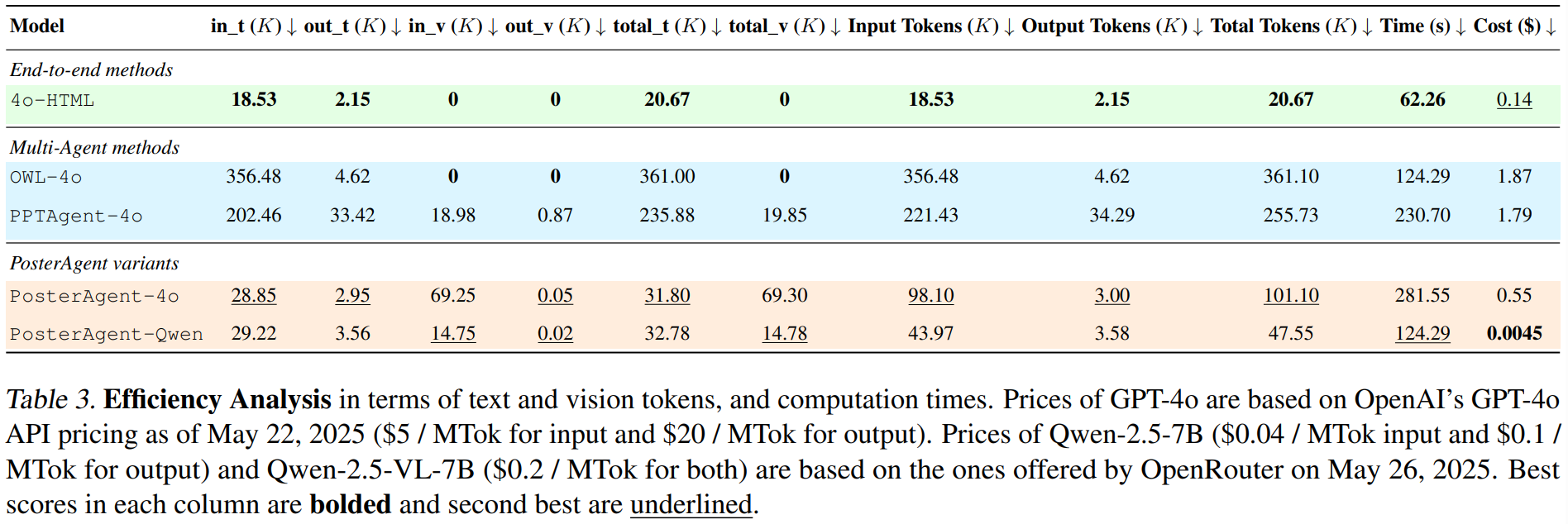
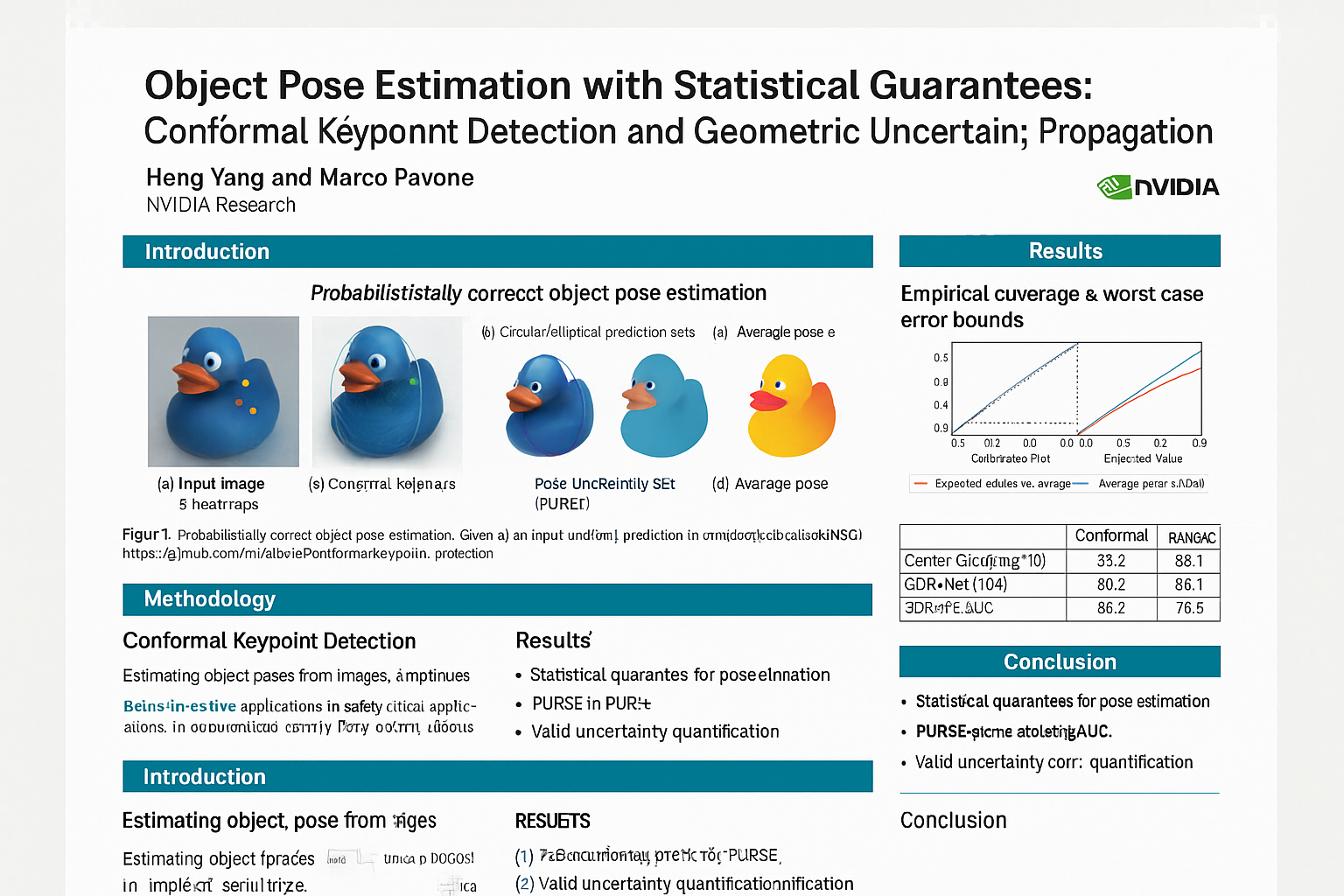
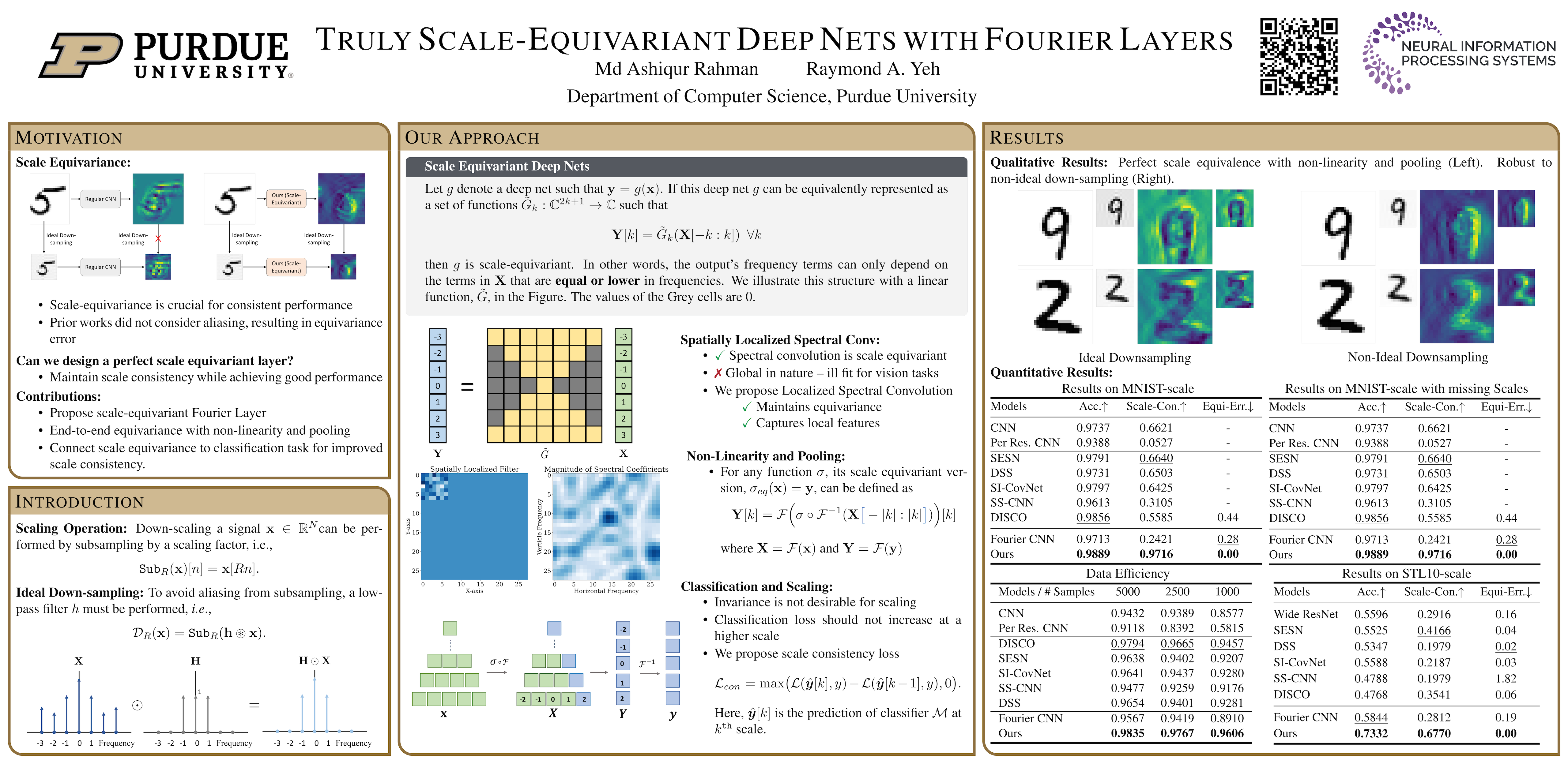
Academic poster generation is a crucial yet challenging task in scientific communication, requiring the compression of long-context interleaved documents into a single, visually coherent page. To address this challenge, we introduce the first benchmark and metric suite for poster generation, which pairs recent conference papers with author-designed posters and evaluates outputs on (i) Visual Quality—semantic alignment with human posters, (ii) Textual Coherence—language fluency, (iii) Holistic Assessment—six fine-grained aesthetic and informational criteria scored by a VLM-as-judge, and notably (iv) PaperQuiz—the poster’s ability to convey core paper content as measured by VLMs answering generated quizzes. Building on this benchmark, we propose PosterAgent, a top-down, visualin-the-loop multi-agent pipeline: the (a) Parser distills the paper into a structured asset library; the (b) Planner aligns text–visual pairs into a binary-tree layout that preserves reading order and spatial balance; and the (c) Painter–Commenter loop refines each panel by executing rendering code and using VLM feedback to eliminate overflow and ensure alignment. In our comprehensive evaluation, we find that GPT-4o outputs—though visually appealing at first glance—often exhibit noisy text and poor PaperQuiz scores, and we find that reader engagement is the primary aesthetic bottleneck, as human-designed posters rely largely on visual semantics to convey meaning. Our fully open-source Paper2Poster pipeline outperforms GPT-4o–based systems across nearly all metrics while consuming 87% fewer tokens. These findings chart clear directions for the next generation of fully automated poster-generation models.



















{kind=link}